
最高フォロワー小説占い
Doc2Vecを使用して、小説の類似度を判定する
【ご注意】
そりゃまあPC壊れることはまずないとは思ってるけど
万一のことがあっても責任を取りません!
あしからず!
はじめに
まず、この方法は、そんなに(びっくりするほど)精度が高いものではありません。
また、手順を見てくださったらご理解いただけるかと思うのですが、
AIは、文章の上手い下手も分かりません。
ちょっぴり当たりやすい「占い」くらいにとらえておくのが良いと思います。
必要なモノ:Google Colaboratory
TIPS
ほんとうだろうか? ほんとうに相関はないんだろうか?
料理が上手い人のカレーのレシピに、必ずターメリック数グラムが含まれているということはないか?
ただ、AIは確かに理解しない。
星の呼吸も、大地の湿り気も、その意味するところを知るはずもない。
数値が近ければ近いほどいいというワケではないことは確かだ。
導入
ステキな小説を読んでため息をつく日々……。
みんなすごいな…………。
文章めちゃウマフォロワーと私って、どのくらい違うんだろう……。
そんなときは、お花畑に行って花弁を引きちぎるか、
代わりにDoc2Vecを使用しましょう。
「似ている」「似ていない」「似ている」「似ていない」……の代わりに、
Doc2Vecを用いて、フォロワーの小説を解析することによって類似度を判定するコトが出来ます。
お花が犠牲にならなくても済む分、ちょっぴり地球に優しいかも知れません。
- データ集め
- 前処理(形態素解析)
- Doc2Vecに取り込む
データ集め
たぶん、インターネッツでDoc2Vecやり方を調べてると、ここがムズカシソウに見えるんじゃないでしょうか。
しょっぱなからニュースサイトの記事を集めてきたり、青空文庫のデータを集めてきてたりしますよね。
ふつう、Doc2Vecをテストするときは大量のデータでガーーーッとやるわけで、
手で集めてたらやってられん作業こそプログラムの出番なんですが、
今回の目的はあくまでもフォロワーときゃっきゃすることなので、こんなにいらないです。
(あと、機械的に大量のデータを収集する行為はサービスによっては禁止されてたりするので、
手でやるのが一番リスクが少ないです)
「Doc2Vecでトレーニングするためにデータを貸してくれないか」と頼みに行きましょう。
Pythonで遊ぶときの課題として、このへんのデータ収集を自動化できると
なんかむちゃくちゃかっこええコトをしているような気がしてすっげ~~~きもちいいんですけど、
とりあえずこのことは忘れましょう。
うっかり誰かから見える……ってことはないはずですが、なるべくなら、公開しているデータを借りるのがベターですね!
とりあえず一本でいいでしょう。
一本テキストファイルを作って、リネームします。
それで比較用のもう一本は……フォロワー諸氏ならば最高SSを既に何本か仕上げているはずであり、手元にじぶんのテキストデータが眠っていると思います。
これでいきましょう。
「my_text.txt」
「follower_text.txt」
って名前で保存しておいて下さい。
TIPS
ちなみに私はオンライン環境というのがいまいち信頼できず、手元に全てがそろっている状態が好きなのでローカルにPython環境を構築して手元でやっています。
(フォロワーの小説をアップロードするわけにもいかないしな……)
前処理
まずは下ごしらえです。Doc2Vecの学習データを作るために、形態素分析というのをしましょう。
日本語の分解にはMecabというのを使います。
!pip install mecab-python3
!pip install unidic
!python -m unidic download
Google Colaboratory上でこれを実行します。これは(毎回)1回だけでいいです。
【はえ~、と思いながら眺める】

入れたら、ちゃんとMecabが入ってるか試してみましょう。
import MeCab【実行例】
import unidic
tagger = MeCab.Tagger()
sample_txt = 'フォロワーと私の最高小説'
result = tagger.parse(sample_txt)
print(result)

見て見て、これが形態素解析だよ!
これだけでも、「オオ~~~ッ」感がありますね。
そんじゃあ、次、このsample_txtを「最高小説.txt」に持ち替えます。
一応、今後のことを考えてTESTっていうフォルダを作って、中に入れました。
ここに読んできたテキストが入るので、sample_txtを持ち替えます。
import MeCab【実行例】
import unidic
my_file = open('/content/TEST/my_text.txt', 'r', encoding='UTF-8')
my_text = my_file.read()
tagger = MeCab.Tagger()
result = tagger.parse(my_text)
print(result)
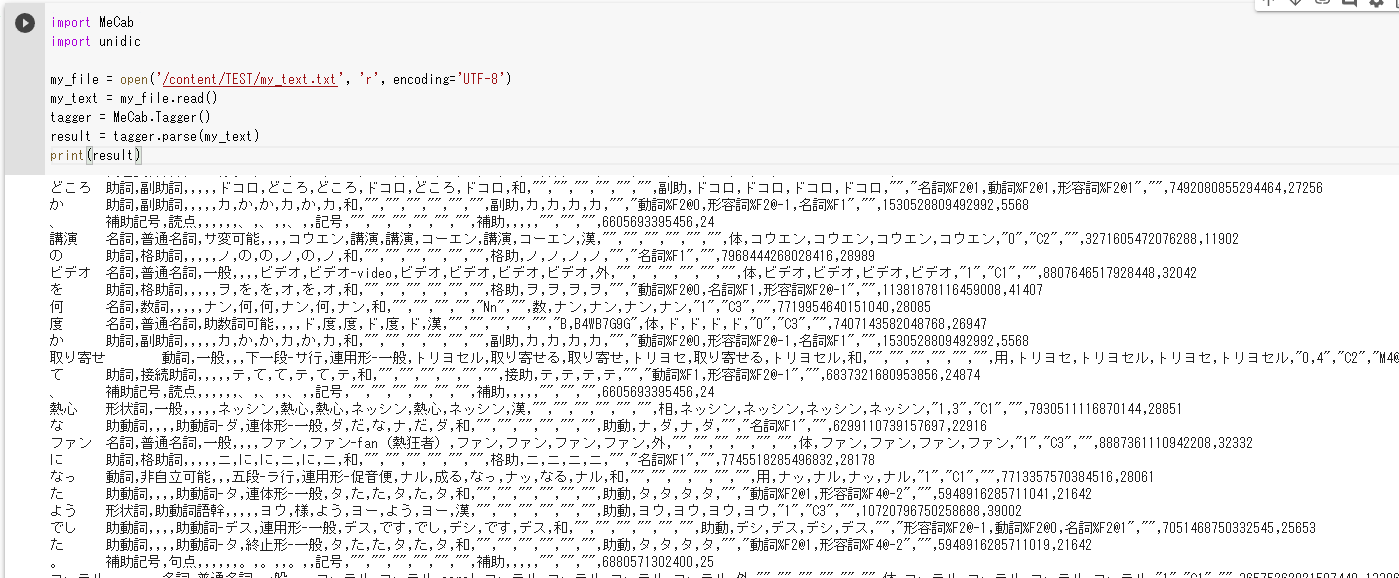
これでファイルの中身を良い感じに形態素解析した部分が見れたと思います。
そんじゃあ、前処理まで出来たので、いよいよDoc2Vecを試してみましょう。
Google Colaboratoryの良いところは、機械学習用のGPUも無料で利用できるところにあります。
そんでもってタグ付するところを関数にして、必要なやつだけ(今回は名詞、動詞、形容詞だけ)加えていきます。
ちょっと話を飛ばします。でや~。
import MeCab
import unidic
from gensim.models.doc2vec import Doc2Vec
from gensim.models.doc2vec import TaggedDocument
#タグ付けしてくれる関数を定義
def split_into_words(doc, name=''):
mecab = MeCab.Tagger()
lines = mecab.parse(doc).splitlines()
words = []
for line in lines:
chunks = line.split('\t')
# 名詞(数詞は除く)、動詞、形容詞のみ加える
if len(chunks) > 1 and (chunks[1].startswith('動詞') or chunks[1].startswith('形容詞') or (chunks[1].startswith('名詞') and not chunks[1].startswith('名詞-数'))):
words.append(chunks[0])
return TaggedDocument(words=words, tags=[name])
#自分の小説を読み込む
train_text = []
target = open('/content/TEST/my_text.txt', 'r', encoding='UTF-8')
test = target.read()
train_text.append(split_into_words(test,'私')) #「私」でタグ付け
#フォロワー(暫定)の小説を読み込む
target = open('/content/TEST/follower_text.txt', 'r', encoding='UTF-8')
test = target.read()
train_text.append(split_into_words(test,'follower')) #「フォロワー」でタグ付け
#Doc2Vecで学習してもらう
#注:ここのパラメータ弄って遊ぶと面白い
model = Doc2Vec(vector_size=100, dm=0, alpha=0.05, min_count=5)
model.build_vocab(train_text)
model.train(train_text, total_examples=len(train_text), epochs=5)
#私とフォロワーの類似度を調べる
print(model.docvecs.similarity("私","follower"))
【実行例】
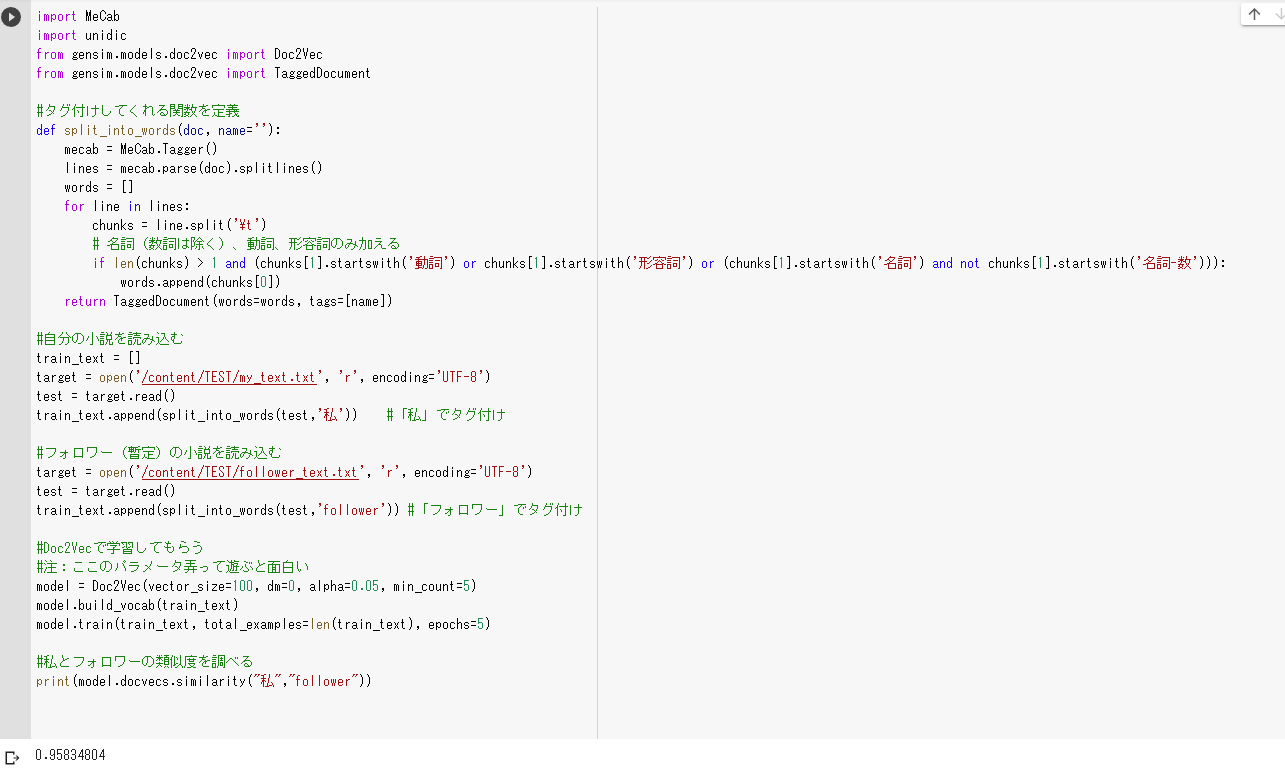 ほい。
ほい。
ここはこちらのQittaの記事を大変参考にしました。
サンプルはどっちも私なので、9割くらい似ていると言われています。
「前書いた話とどんくらいテイスト離れたかな~」だとか、色々遊んでみましょう。
納得いく結果がでなかった?
パラメータを弄って「ハイ」と言わせるんだ。マスターは私だ。
TIPS
1つのサンプルデータじゃ物足りない。フォロワーのすべてを知りたい。そんなふうにお考えの方もあるかと思います。
その場合はテキストファイルに追記しまくって長くするんじゃなくって、
Pythonちゃんの「このフォルダーにある全てのテキストファイルを列挙して追記していく」
みたいなことしましょう。
あっぜんぜん分からん人は「余ったレモンカードでもう一品こしらえてみましょう」
みたいなことを言われた私みたいになってそうですが、
要するに何とかする方法はあるのでそっちに行った方が楽というやつですね!
2021/11/25
(参考文献)
https://radimrehurek.com/gensim/models/doc2vec.html
GENSIM Doc2Vecドキュメント
https://atmarkit.itmedia.co.jp/ait/articles/2102/05/news027.html
『[文章生成]MeCabをインストールして分かち書きを試してみよう』itmedia
https://recruit.gmo.jp/engineer/jisedai/blog/doc2vec-evaluation/
『Doc2Vecをいい感じに評価したい』GMO INTERNET GROUP
https://qiita.com/minnsou/items/37e3155c92103dae04f4
『ニューラルネットとDoc2Vecを使った作者推定(青空文庫)』Qitta
2021/11/24 02:32:47(最終観覧)